
Hadoop 簡介
Hadoop 是一個開源的分散式存儲和處理框架,常用於巨量資料集的處理,透過 Hadoop,我們能將多個機器結合成群集(cluster),充分利用機器的本地存儲與計算資源,並能夠以平行計算的方式來處理資料。
Hadoop 的歷史最早可以追溯回 Google 所發表的三篇論文,分別是MapReduce、GFS (Google File System) 與 BigTable,後由 Doug Cutting 與 Mike Cafarella 對論文進行了開源實現,現為 Apache 基金會下的專案項目。
小知識:Hadoop 的名字與logo ,其靈感來自於 Doug Cutting 兒子的黃色玩具象

Hadoop 架構
Hadoop 的核心架構主要有三,分別是 HDFS (Hadoop 分散式檔案系統)、YARN (Yet Another Resource Negotiator) 與 MapReduce:
HDFS (Hadoop 分散式檔案系統)
HDFS 是基於流式數據訪問的分散式文件管理系統,支持超大型文件存儲 (TB、PB以上),可以運行在廉價商用集群上,透過網路進行連接,HDFS 作為一抽象層,建構在這些集群網路上,對文件進行統一的管理,其優點有高容錯性、高擴展性以及高可用性等。
這裡的流式數據訪問與前幾天提到的流處理計算並不相同,指的是一種訪問硬碟文件的模式。與之相對德是隨機數據訪問
-
流式數據訪問
數據塊之間有一順序,僅須尋址一次接著依序讀取,數據只能一次寫入、多次讀取。因為是按一定的順序訪問數據,所以不需要將所有數據讀入記憶體,可以針對單一數個據塊進行操作,適合大規模數據的處理。
-
隨機數據訪問
數據塊之間通常不存在順序,操作時需先將數據讀入記憶體,透過索引結構,可以快速訪問和檢索數據集中的特定記錄,傳統的關聯式資料庫多是屬於隨機數據訪問。
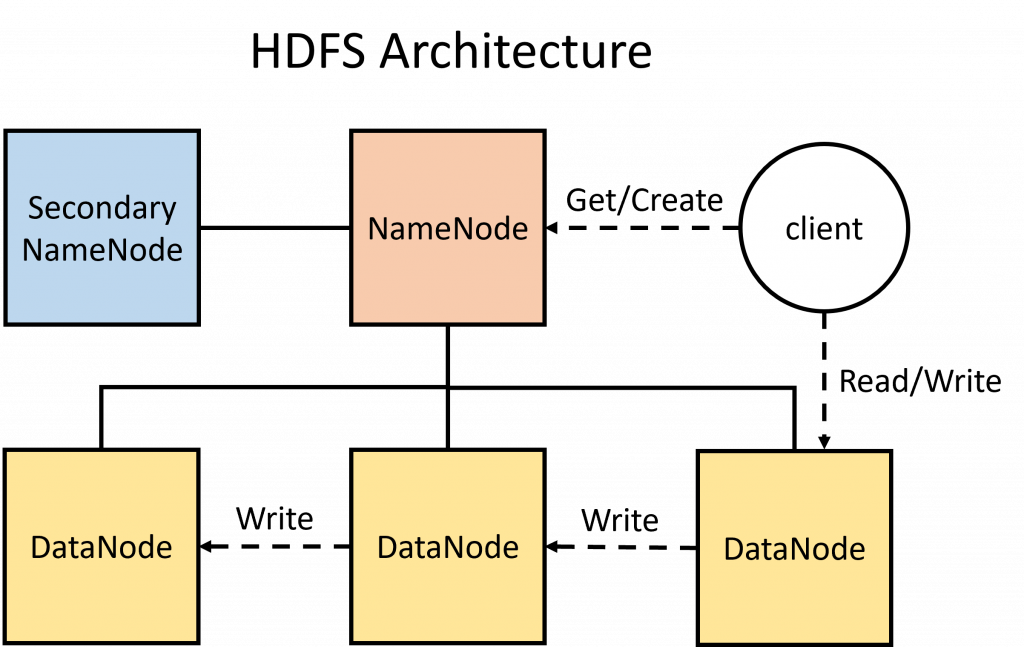
架構上,HDFS 屬於典型的主從架構,主要由3種節點構成,分別是 NameNode、SecondaryNameNode 與 DataNode,一個基本的 HDFS 架構中通常會包含一個 NameNode、一個 SecondaryNameNode 與至少一個 DataNode,HDFS 會將文件切成數據塊 (block),分散存儲在各個 DataNode,並透過NameNode 來管理這些數據塊,SecondaryNameNode 則用來協助 NameNode 進行數據的合併與同步備援。
-
NameNode
- 是主從架構中的主節點,負責管理整個檔案系統的目錄與文件,由兩個文件組成,分別是FSImage (File System Image) 與 Edit Log,前者是整個系統的完整快照,後者則是文件系統的更新日誌。
- 由於 FSImage 是一個非常龐大的檔案,因此每次發生數據更新都直接更新 FSImage 是非常耗時的,所以會先更新至 Edit Log 中,之後再透過 SecondaryNameNode 將兩者 合併。
-
SecondaryNameNode
- 是 NameNode 的輔助節點,負責 FSImage 與 Edit Log 的合併,具體做法是由 SecondaryNameNode 將兩個檔案讀取到節點中,在節點中將兩個檔案合併完成後,再將新的 FSImage 傳回 NameNode。
- SecondaryNameNode 不是 NameNode 的熱備份,並不能在 NameNode 故障時直接接管工作。
-
DataNode
- 是主從架構中的從節點,負責數據塊的 I/O 操作,雖說 DataNode 透過 NameNode 進行管理,但實際上一樣會是 client 直接對 DataNode 進行操作。
- 一個數據塊通常會被存放在不只一個 DataNode 中,當 client 將數據塊寫入一個 DataNode 後,該 DataNode 會將數據塊也寫入其他 DataNode。
- DataNode 除了等待 NameNode 的指示外,也會定期向 NameNode 匯報數據塊的情況,有助於快速檢測故障、數據恢復。
YARN (Yet Another Resource Negotiator)
Hadoop 的資源管理原先由 MapReudce 負責,直到 Hadoop 2.0 後才獨立出 YARN,是 Hadoop 的資源管理系統,讓 MapReduce 能專心做數據相關的計算。
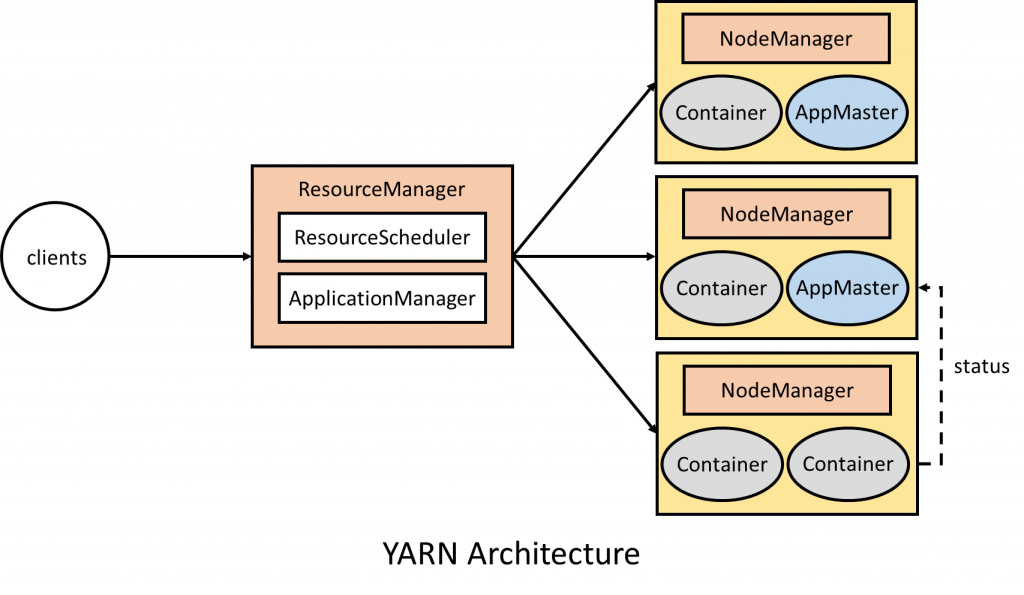
YARN 也是採用主從架構,主要由 ResourceManager、NodeManager、ApplicationMaster 以及 Container 所組成:
-
ResourceManager (資源管理器)
- 是主從架構中的主節點,負責整個系統的資源管理與調度,包含 ResourceScheduler 與 ApplicationManager
- ResourceScheduler 負責資源的調度,將系統資源分配給應用程序
- ApplicationManager 負責管理系統中的應用程序,包括提交應用程式、與 ResourceScheduler 協商資源以啟動應用程式管理器、監控應用程式管理器的狀態等。
-
NodeManager (節點管理器)
- 是主從架構中的從節點,負責每個節點上的資源與任務管理,接收應用程式管理器的請求來啟動或停止容器。
-
ApplicationMaster (應用程式管理器)
- 負責與資源管理器協商資源,並與節點管理器溝通以執行應用程式中的所有任務
- 負責監控應用程式的執行狀況,並向資源管理器回報狀態
-
Container (容器)
- 概念跟 docker 中的容器差不多,將特定資源進行封裝,是節點中實際執行任務的地方,也因此任務只能使用容器內的資源
YARN 不只能與 MapReduce 做搭配,其更是一個通用的資源管理系統,多種大數據處理框架都能部署在 YARN 之上,如:Spark on YARN、Flink on YARN。
MapReduce
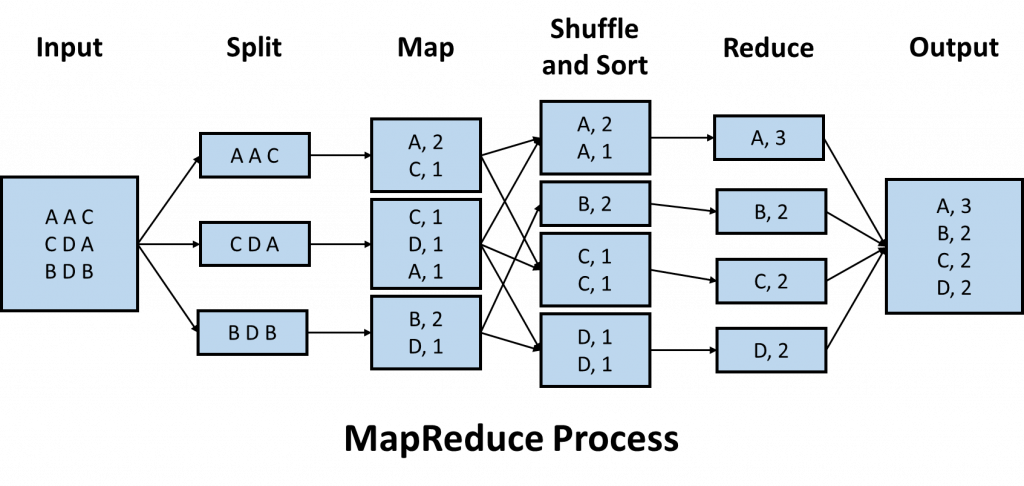
MapReduce 是一種分散式計算的程式設計模型 (programming model),也是 Hadoop 預設的計算模式,有學過演算法的話可以把他想成應用在巨量數據處理的分而治之 (Divide and Conquer),有 Map 與 Reduce 兩個主要階段,具體步驟為:
-
Split:將數據切割為小部分。
-
Map:將數據切割為更小部分,並對每個部分進行初步的計算,並將結果轉換為鍵值對 (key-value pair)。
-
Shuffle and Sort:將鍵值對進行分組與排序,使相同鍵的鍵值對能夠被連續處理。
-
Reduce:對已分組的鍵值對進行聚合操作,並產出結果,通常是另一組鍵值對。
預告
下一篇文章是 Hadoop 的安裝教學~
參考資料
《大數據技術原理與應用:概念、存儲、處理、分析與應用》- 林子雨
《實戰大數據 (Hadoop + Spark + Flink) 從平台構建到交互式數據分析 (離線/實時)》- 楊俊


 iThome鐵人賽
iThome鐵人賽